How does audio describe the world around us? In this paper, we explore the task of generating an image of the visual scenery that sound comes from. However, this task has inherent challenges, such as a significant modality gap between audio and visual signals, and audio lacks explicit visual information inside. We propose Sound2Scene, a model that works by scheduling the learning procedure of each model component to associate audio-visual modalities despite their information gaps. The key idea is to enrich the audio features with visual information by learning to align audio to visual latent space. Thereby, we translate input audio to visual feature, followed by a powerful pre-trained generator to generate an image. We further incorporate a highly correlated audio-visual pair selection method to stabilize the training. As a result, our method demonstrates substantially better quality in a large number of categories on VEGAS and VGGSound datasets, compared to the prior arts of sound-to-image generation. Besides, we show the spontaneously learned output controllability of our method by applying simple manipulations on the input in the waveform space or latent space.
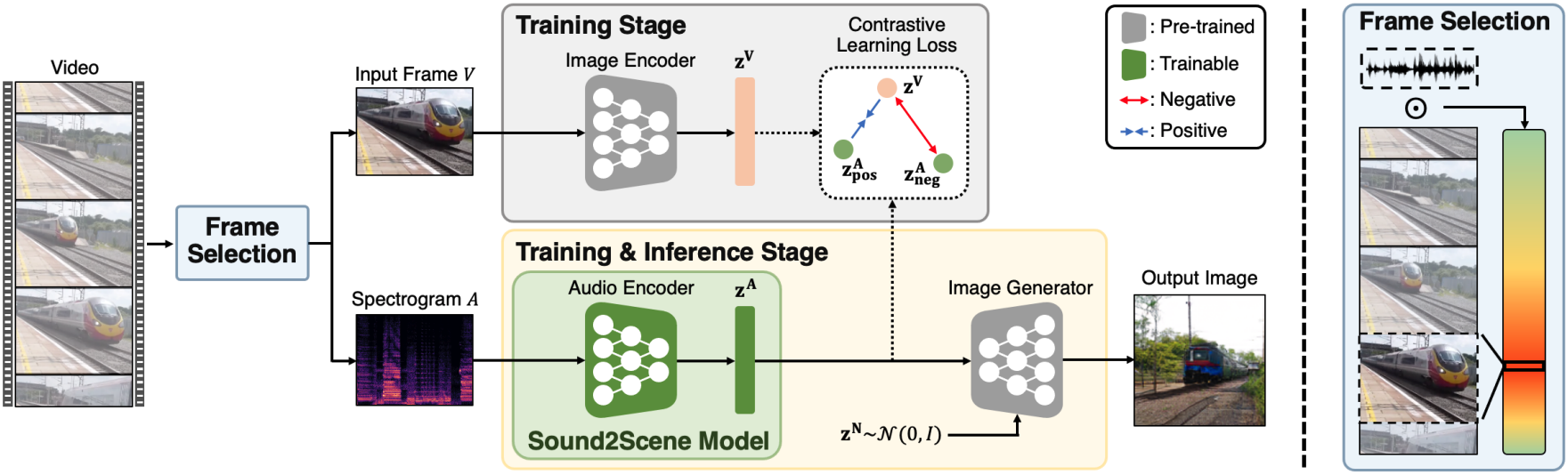
We propose Sound2Scene and its training procedure for generating images from the input sound. First, given an image encoder pre-trained in a self-supervised way, we train a conditional generative adversarial network to generate images from visual embedding vectors of the image encoder. We then train an audio encoder to translate an input sound to its corresponding visual embedding vector, by aligning the audio to the visual space. Afterwards, we can generate diverse images from sound by translating from audio to visual embeddings and synthesizing an image. Since Sound2Scene must be capable of learning from challenging in-the-wild videos, we use sound source localization to select moments in time that have strong cross-modal associations.
Sound2Scene generates diverse images in a wide variety of categories from generic input sounds.
 Churchbell Ringing  Printer |
 Cow Lowing  Owl Hooting |
 Lawn Mowing  Tractor Digging |
 Volcano Explosion  Fire Truck |
 Scuba Diving  Stream Burbling |
 Snake Hissing  Skiing |
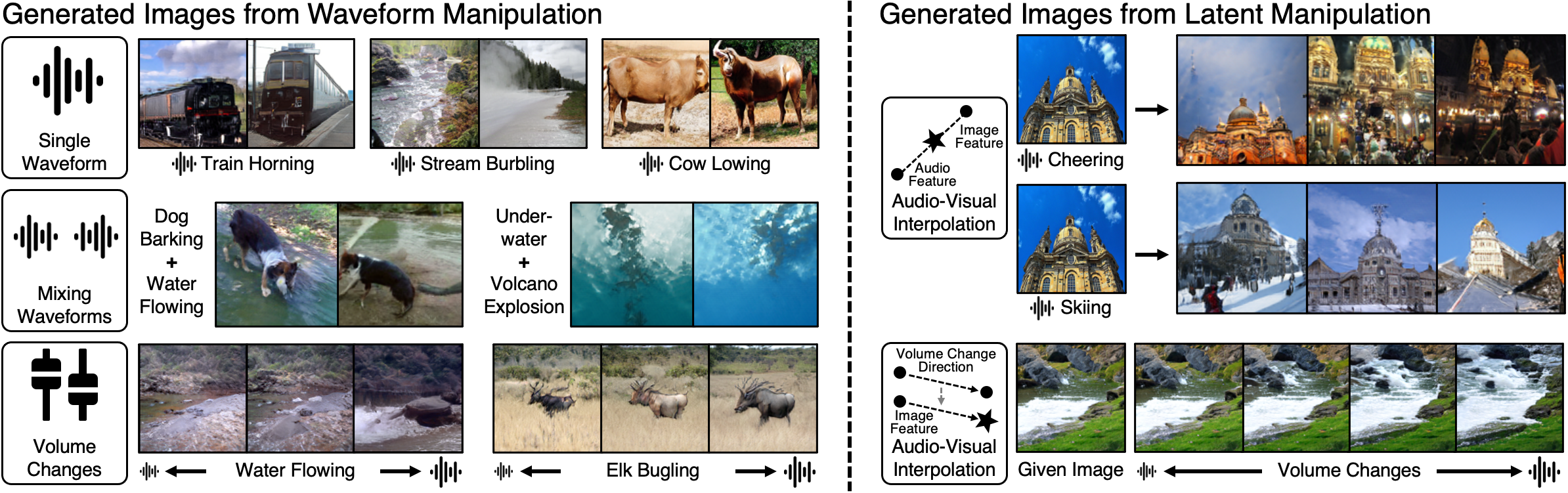
Just as humans can roughly predict the distance or the size of an instance by the volume of the sound, Sound2Scene can understand the relation between the volume of the audio and visual changes.
⚠ Please pause the video and adjust the volume. There are large volume sounds.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Sound2Scene can capture the existence of multiple sound sources and reflect them in the generated images.
  Dog+Water Flowing |
  Baby+Water Flowing |
  Train+Skiing |
  Train+Hail |
  Bird+Skiing |
  Bird+Hail |
Sound2Scene can mimic the camera movement by placing the object further as the wind sound gets larger.
  |
  |
  |
  |
  |
With a simple latent interpolation between audio and visual features, Sound2Scene can generate novel images by conditioning on both audio-visual signals.
|
Input  |
Generated Images  |
Input |
Generated Images  |
 |
 |
|
 |
 |
 |
|
 |
By moving the visual feature toward the direction of the volume difference between the two audio features, Sound2Scene can edit the original image with the paired sound.


Volume Decrease Direction 
Volume Decrease Direction 
Volume Decrease Direction |



|


Volume Increase Direction 
Volume Increase Direction 
Volume Increase Direction |
@inproceeding{sung2023sound,
author = {Sung-Bin, Kim and Senocak, Arda and Ha, Hyunwoo and Owens, Andrew and Oh, Tae-Hyun},
title = {Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023}
}This work was supported by IITP grant funded by Korea government (MSIT) (No.2021-0-02068, Artificial Intelligence Innovation Hub; No.2022-0-00124, Development of Artificial Intelligence Technology for Self-Improving Competency-Aware Learning Capabilities). The GPU resource was supported by the HPC Support Project, MSIT and NIPA.